


изучаем
данные
день 02
Сегодня мы поговорим:
о том, как студенты РЭУ им. Г. В. Плеханова используют Visiology
как выбрать правильную модель данных для своих задач
как подключить свои данные к Visiology и настроить связи





Сила Visiology для студентов
/ История успеха
к.э.н., доцент кафедры прикладной информатики
и информационной безопасности, РЭУ имени Г. В. Плеханова
и информационной безопасности, РЭУ имени Г. В. Плеханова
Наталья Середенко

На кафедре прикладной информатики и информационной безопасности мы готовим будущих системных аналитиков, программистов, специалистов по информационным системам, руководителей проектов.
В образовательной программе есть курс по проектированию информационно-аналитических систем, на котором студенты учатся проводить аналитику: создавать модели данных, писать вычисления, разрабатывать интерактивные дашборды. Раньше курс был построен на инструменте Microsoft Power BI, но, когда остро встал вопрос импортозамещения, мы начали искать вендоров среди российских компаний.
В образовательной программе есть курс по проектированию информационно-аналитических систем, на котором студенты учатся проводить аналитику: создавать модели данных, писать вычисления, разрабатывать интерактивные дашборды. Раньше курс был построен на инструменте Microsoft Power BI, но, когда остро встал вопрос импортозамещения, мы начали искать вендоров среди российских компаний.
На кафедре прикладной информатики и информационной безопасности мы готовим будущих системных аналитиков, программистов, специалистов по информационным системам, руководителей проектов.
В образовательной программе есть курс по проектированию информационно-аналитических систем, на котором студенты учатся проводить аналитику: создавать модели данных, писать вычисления, разрабатывать интерактивные дашборды. Раньше курс был построен на инструменте Microsoft Power BI, но, когда остро встал вопрос импортозамещения, мы начали искать вендоров среди российских компаний.
В образовательной программе есть курс по проектированию информационно-аналитических систем, на котором студенты учатся проводить аналитику: создавать модели данных, писать вычисления, разрабатывать интерактивные дашборды. Раньше курс был построен на инструменте Microsoft Power BI, но, когда остро встал вопрос импортозамещения, мы начали искать вендоров среди российских компаний.

Изучив актуальные исследования рынка BI-инструментов, мы обратились к коллегам из Visiology. Наши цели совпадали: мы хотим выпускать специалистов с практическим опытом, которые нужны рынку, а Visiology – внедрять отечественный продукт. Мы заключили сотрудничество меньше года назад, но уже достигли серьезных результатов.
Помимо того, что Visiology используется в образовательном процессе и является практическим инструментом на учебных занятиях, коллеги предоставляют студентам не только практику у себя, но и у своих бизнес-заказчиков, у которых внедрен Visiology. Это очень ценное направление нашего сотрудничества, так как студентам важно получать реальный опыт рабочих задач.
Кроме того, Visiology используется и как инструмент анализа данных в научных исследованиях и статьях. Студенты пишут выпускные квалификационные работы на основе Visiology, применяя полученные знания в разных секторах бизнеса — от банковской отрасли и ритейла до процессов в сельском хозяйстве.

Мы находимся в постоянном диалоге вместе с партнерами из Visiology и очень рады обмениваться обратной связью. Например, на самом первом занятии с пилотной группой студентов мы спонтанно провели сессию по подготовке новых идей для развития продукта: собрали около 15 предложений и отправили их коллегам, которые воодушевились и сразу же передали новые идеи в команду разработки.

20 ноября 2023 года РЭУ им. Г. В. Плеханова получили награду за самую быструю миграцию с западного BI на конференции ViRush.
На кафедре готовят проектировщиков информационных систем в широком смысле слова: в рамках проектных заданий студенты создают целый информационный комплекс, начиная от учетной системы и заканчивая финальной визуализацией данных. То есть они сами моделируют тестовые данные, проводят их учет, преобразовывают и аналитически обрабатывают в ETL-инструменте (здесь мы работаем с еще одним российским вендором и нашим партнером Loginom), а с помощью Visiology создают конечные дашборды.

Таким образом, у студентов появляется не только понимание работы с какой-то отдельной системе, но видение общего архитектурного ландшафта и того, какое место каждая система занимает в информационном комплексе предприятия.
Мы проводили опрос среди студентов, с каким классом систем им нравится работать больше всего: учетные системы, системы ETL или же BI. Большинство выбирало системы класса BI — там не только технология, но и красота, которую видишь.
Создаем созвездия данных
/ Теория
Перед визуализацией данных вам нужно подключить имеющиеся источники и составить модель данных. Правильно спроектированная структура данных имеет решающее значение для аналитики по нескольким важным причинам:
- значительно ускоряет выполнение запросов и извлечение данных за счет оптимизации соединений (в схемах вида «звезда» и «созвездие»),
- упрощает ее понимание для аналитиков и конечных пользователей. Это важно для быстрого доступа к данным и разработки интуитивно понятных отчетов и дашбордов,
- легко поддерживает гибкость и масштабируемость с ростом данных и изменения аналитических задач,
- обеспечивает целостность данных и более простую интеграцию новых источников данных, включая объединение разных источников.
Для своих аналитических проектов выбирайте схему «звезда» или «созвездие», чтобы сделать аналитику как можно более эффективной с точки зрения производительности и поддержки. Мы расскажем об особенностях этих схем ниже, а выбор подходящей должен основываться на специфике бизнес-задач, объемах и сложности обрабатываемых данных, а также имеющихся ресурсах, доступных для поддержки и развития хранилища данных.
О схеме «звезда»
«Звезда» — это модель организации данных, в которой таблица с фактами находится в центре, а окружающие ее измерения расположены на лучах, связанных с таблицей фактов.

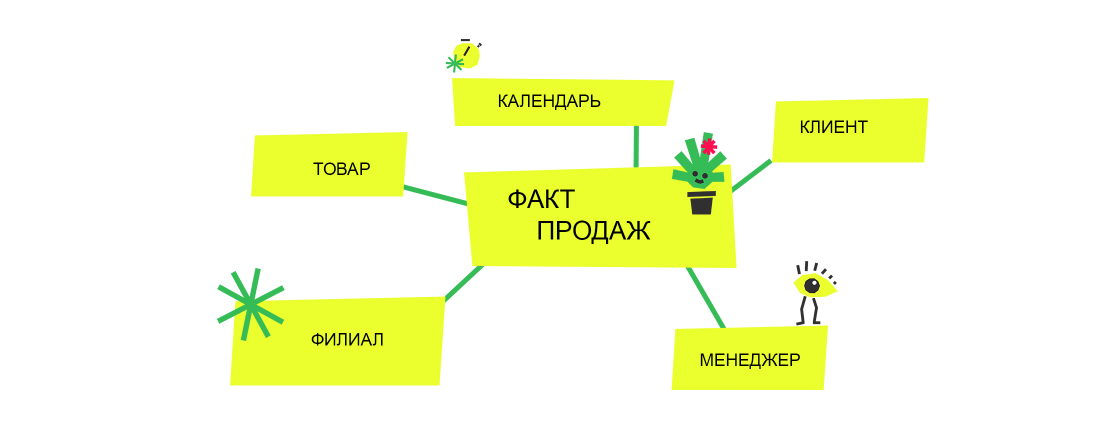
Пример схемы типа «звезда».
Факт-таблица содержит ключевые метрики бизнеса (продажи, расходы, количество), а также внешние ключи, которые соединяют эту таблицу с таблицами измерений. Таблицы измерений содержат атрибуты, характерные для измерений (например, время, клиенты, продукты, географические данные), которые позволяют проводить сегментацию и группировку данных фактов для анализа.
Давайте рассмотрим на примерах. Например, в ритейл-отрасли:
Факт-таблицей будет таблица Продаж с данными по каждой транзакции: количество проданных товаров, цена, общая сумма продаж;
А таблица измерений – Время (дата, месяц, квартал, год), Продукты (наименование товара, категория, бренд), Магазин (название, местоположение, регион), Клиенты (возраст, пол, тип клиента).
Давайте рассмотрим на примерах. Например, в ритейл-отрасли:
Факт-таблицей будет таблица Продаж с данными по каждой транзакции: количество проданных товаров, цена, общая сумма продаж;
А таблица измерений – Время (дата, месяц, квартал, год), Продукты (наименование товара, категория, бренд), Магазин (название, местоположение, регион), Клиенты (возраст, пол, тип клиента).
Нажмите, чтобы посмотреть еще примеры по схеме «звезда»
В банках:
Факт-таблица – таблица Транзакций с данными о сумме транзакции, типе операции, комиссиях
А измерения – Время (дата, месяц, год), Клиенты (имя, сегмент, регион), Счета (тип счета, валюта), Филиалы (название, местоположение)
В телекоммуникациях таблицы будут такими:
Факт-таблица – со звонками (данные о длительности звонков, использованных минутах, стоимости)
Измерения – Время (дата, время суток), Абоненты (имя, план, регион), Устройства (модель, производитель), Услуги (тип услуги, тарифный план)
И в производстве:
Факт-таблица – Производственные операции (данные о количестве произведенной продукции, времени производства, затратах)
Измерения – Время (смена, день, месяц), Продукты (наименование, категория), Оборудование (тип, модель), Рабочие (имя, категория)
Как видно, факт-таблица – это основная транзакционная таблица, куда поступают постоянно добавляемые данные. Таблицы измерения же выступают в качестве справочников.
Факт-таблица – таблица Транзакций с данными о сумме транзакции, типе операции, комиссиях
А измерения – Время (дата, месяц, год), Клиенты (имя, сегмент, регион), Счета (тип счета, валюта), Филиалы (название, местоположение)
В телекоммуникациях таблицы будут такими:
Факт-таблица – со звонками (данные о длительности звонков, использованных минутах, стоимости)
Измерения – Время (дата, время суток), Абоненты (имя, план, регион), Устройства (модель, производитель), Услуги (тип услуги, тарифный план)
И в производстве:
Факт-таблица – Производственные операции (данные о количестве произведенной продукции, времени производства, затратах)
Измерения – Время (смена, день, месяц), Продукты (наименование, категория), Оборудование (тип, модель), Рабочие (имя, категория)
Как видно, факт-таблица – это основная транзакционная таблица, куда поступают постоянно добавляемые данные. Таблицы измерения же выступают в качестве справочников.
О схеме «Созвездие»
«Созвездие», или схема множественных звезд — это более сложная форма хранения данных, чем традиционная «звезда». В «созвездии» несколько факт-таблиц связаны с общими таблицами измерений, позволяя таким образом анализировать данные из различных бизнес-процессов в рамках одной структуры.
В «созвездии» связи между фактами и измерениями более сложные. У каждой факт-таблицы могут быть как свои уникальные измерения, так и общие, которые она делит с другими факт-таблицами. Это позволяет проводить более комплексный анализ данных.
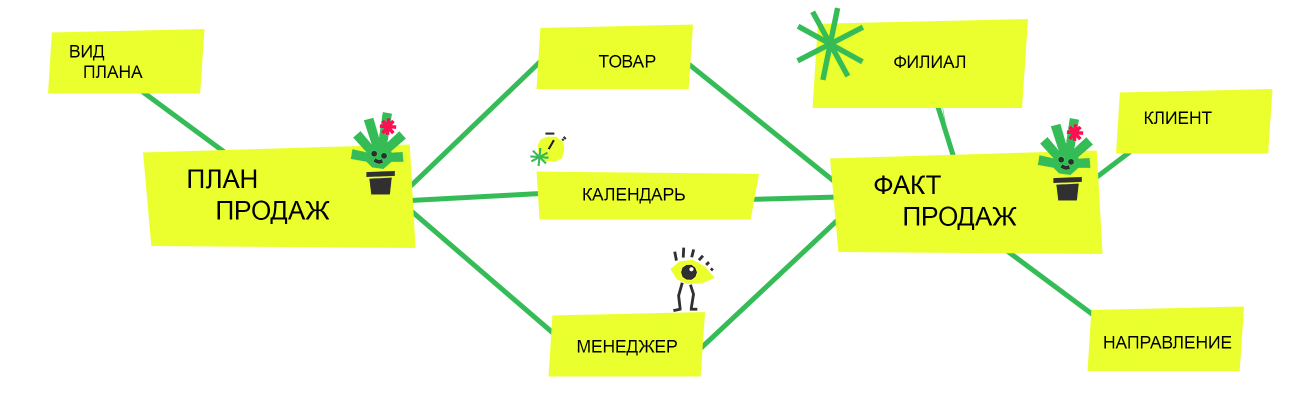
Пример схемы типа «созвездие».
В схеме «созвездие» связи будут несколько другими, чем в схеме «звезда». Например, на том же примере ритейла:
Факт-таблицы могут включать данные по Продажам, Запасам на складе, Возвратам и Заказам. А общие измерения могут быть такими же как в «звезде» и включать Продукты, Магазины, Время и Клиентов. Аналитики могут использовать эту схему для оценки общей производительности, анализа трендов продаж во времени, оптимизации уровней запасов и понимания паттернов покупок клиентов.
Факт-таблицы могут включать данные по Продажам, Запасам на складе, Возвратам и Заказам. А общие измерения могут быть такими же как в «звезде» и включать Продукты, Магазины, Время и Клиентов. Аналитики могут использовать эту схему для оценки общей производительности, анализа трендов продаж во времени, оптимизации уровней запасов и понимания паттернов покупок клиентов.
И еще немного примеров в других отраслях...
В банках:
Факт-таблицы могут охватывать различные финансовые операции, инвестиции, кредиты и транзакции. Общие измерения могут включать клиентов, счета, время и филиалы. Схема «созвездие» позволяет финансовым аналитикам анализировать риски, доходность инвестиций и паттерны транзакций с различных сторон.
В процессах производства:
Факт-таблицы могут содержать информацию о производственных процессах, себестоимости, обслуживании оборудования и управлении качеством. Общие измерения могут включать продукты, машины, рабочие смены и время. С помощью схемы «созвездие» можно проводить мониторинг и оптимизацию производственных процессов, а также анализировать простои и эффективность работы оборудования.
В телекоммуникациях:
Факт-таблицы могут содержать данные о звонках, использовании данных, обслуживании клиентов и сетевом трафике. Общие измерения могут включать абонентов, временные периоды, географические регионы и сервисные планы. Аналитики могут использовать схему для анализа паттернов использования, прогнозирования нагрузки на сеть и улучшения качества обслуживания клиентов.
Факт-таблицы могут охватывать различные финансовые операции, инвестиции, кредиты и транзакции. Общие измерения могут включать клиентов, счета, время и филиалы. Схема «созвездие» позволяет финансовым аналитикам анализировать риски, доходность инвестиций и паттерны транзакций с различных сторон.
В процессах производства:
Факт-таблицы могут содержать информацию о производственных процессах, себестоимости, обслуживании оборудования и управлении качеством. Общие измерения могут включать продукты, машины, рабочие смены и время. С помощью схемы «созвездие» можно проводить мониторинг и оптимизацию производственных процессов, а также анализировать простои и эффективность работы оборудования.
В телекоммуникациях:
Факт-таблицы могут содержать данные о звонках, использовании данных, обслуживании клиентов и сетевом трафике. Общие измерения могут включать абонентов, временные периоды, географические регионы и сервисные планы. Аналитики могут использовать схему для анализа паттернов использования, прогнозирования нагрузки на сеть и улучшения качества обслуживания клиентов.
Типы соединения таблиц
Типы соединений таблиц в базах данных определяют, как данные из одной таблицы связаны с данными из другой таблицы. Понимание этих соединений важно для аналитики, так как они влияют на способы объединения, анализа и интерпретации данных. Вот два основных типа соединений:
- один к одному (1:1)Здесь каждая строка в одной таблице соответствует ровно одной строке в другой таблице, и наоборот. Такие соединения чаще всего используются для разделения данных для улучшения организации, управления и безопасности. В аналитике соединения 1:1 не так распространены, поскольку в большинстве случаев информацию можно хранить в одной таблице. Однако если информация разделена из соображений безопасности или производительности, соединение 1:1 позволяет аналитикам собирать полную картину, объединяя данные из разных таблиц.
Например, в одной таблице хранятся данные о сотрудниках (имя, должность), а в другой — конфиденциальные данные (номер социального страхования), при этом каждый сотрудник имеет уникальный идентификатор, который используется для соединения записей. - один ко многим (1:n)Это наиболее часто встречающийся тип связи, при котором каждая строка в одной таблице (обычно называемой «родительской») может быть связана с одной или несколькими строками в другой таблице (называемой «дочерней»). Это основной тип соединения, используемый в схемах «звезда» и «снежинка» в хранилищах данных.
Например, таблица «Заказы» содержит уникальные записи каждого заказа, а таблица «Позиции заказа» содержит все товары, которые были заказаны в рамках каждого заказа. Каждая позиция связана с одним заказом, но каждый заказ может содержать множество позиций.
Пример схем вида один к одному и один ко многим.
Соединения 1:n позволяют аналитикам проводить агрегацию данных и анализировать данные на разных уровнях детализации. Например, можно считать общую сумму продаж по всем позициям для каждого заказа или же анализировать продажи на уровне отдельных товаров внутри заказов. Это обеспечивает гибкость при подготовке отчетов.
Посмотрите подробное видео-объяснение о том, что такое многомерная модель данных, на YouTube-канале Visiology.
Многомерная модель данных
Способы загрузки данных
Процесс загрузки данных в аналитическую систему, известный как ETL (Extract, Transform, Load — извлечение, трансформация, загрузка), является ключевым этапом в управлении данными и бизнес-аналитике. Этот процесс включает в себя несколько шагов, начиная со сбора данных из различных источников и заканчивая их загрузкой в аналитическую систему для дальнейшего анализа.
- подготовка источника данныхДанные могут поступать из множества источников, включая операционные системы, транзакционные базы данных, систем CRM (Customer Relationship Management) и ERP (Enterprise Resource Planning), внешние данные (например, социальные сети, публичные данные, данные от партнеров), IoT (Internet of Things) устройства и многие другие. Они могут быть структурированными, полуструктурированными или неструктурированными и могут находиться в различных форматах, таких как текстовые файлы, электронные таблицы, JSON, XML.
Вам необходимо знать, откуда вы получаете данные: проверять их на качество и актуальность, возможность объединения и интеграции, соответствие стандартам конфиденциальности и защиты данных, таким как GDPR или HIPAA. - извлечение данных (extract)На этом этапе данные извлекаются из их исходных источников. Извлечение может быть выполнено в реальном времени или пакетно, в зависимости от требований бизнеса и характеристик источника данных.
- трансформация данных (transform)После извлечения данные трансформируются для обеспечения их согласованности и подготовки к анализу. Этот этап может включать очистку данных от ошибок и дубликатов, конвертацию форматов, нормализацию, обогащение данных (например, путем добавления дополнительной информации), фильтрацию и агрегацию.
- загрузка данных (load)Наконец, обработанные данные загружаются в целевую аналитическую систему, которая может быть хранилищем данных, data lake или многомерным кубом OLAP. Этот процесс также может быть выполнен в реальном времени или в пакетном режиме.
В контексте работы с Visiology важно помнить, что доступен только этап «Load», все остальные этапы происходят до и осуществляются при помощи внешних инструментов.
В Visiology доступно несколько источников загрузки данных — загрузка файлов CSV и XLSX в систему довольно проста, вы сможете это сделать при помощи нашей документации. В случае загрузки данных из внешней базы вам потребуется настроить подключение, которое также можно настроить по инструкции по ссылке.
Создаем свою модель данных
/ Практика
На предыдущем уроке вы могли выбрать одну из представленных задач, а самые любопытные из вас — взять на выполнение обе задачи. Мы будем выполнять практическое задание постепенно каждый день, чтобы в конце получить полноценный проект.
В качестве практики сегодня вам нужно загрузить и создать модель данных исходя из представленных таблиц.
Если у вас нет доступа к учебному стенду Visiology, откройте материалы Подготовительного дня 00 и выполните инструкцию по настройке доступа.
В качестве практики сегодня вам нужно загрузить и создать модель данных исходя из представленных таблиц.
Если у вас нет доступа к учебному стенду Visiology, откройте материалы Подготовительного дня 00 и выполните инструкцию по настройке доступа.
Вариант 1.
Электроавто
Электроавто
Вы являетесь руководителем в компании-операторе сети электрических зарядных станций для автомобилей. Перед вами стоит две задачи:
01. Дать удобный доступ к информации для пользователей вашего сервиса, в которой бы отражалась информация о зарядных станции, времени и скорости зарядке, загруженности по дням недели и т. п.
02. Для внутренних целей, иметь актуальную информацию дефициту/профициту потребления электроэнергии, загруженности зарядных станций и т. п.
> Скачайте датасет по ссылке
01. Дать удобный доступ к информации для пользователей вашего сервиса, в которой бы отражалась информация о зарядных станции, времени и скорости зарядке, загруженности по дням недели и т. п.
02. Для внутренних целей, иметь актуальную информацию дефициту/профициту потребления электроэнергии, загруженности зарядных станций и т. п.
> Скачайте датасет по ссылке
Вариант 2.
Онлайн-кинотеатр
Онлайн-кинотеатр
Вы являетесь аналитиком онлайн-кинотеатра.
Перед вами стоит две задачи:
01. Дать удобный доступ к информации по рейтингу фильмов, с возможностью различной параметризации по запросам пользователя
02. Иметь инструмент, который поможет проанализировать сезонность и прибыльность фильмов для кинотеатра с целью оперативной рекламы.
> Скачайте датасет по ссылке
Перед вами стоит две задачи:
01. Дать удобный доступ к информации по рейтингу фильмов, с возможностью различной параметризации по запросам пользователя
02. Иметь инструмент, который поможет проанализировать сезонность и прибыльность фильмов для кинотеатра с целью оперативной рекламы.
> Скачайте датасет по ссылке
Ответы с реализацией модели данных присылайте скриншотом в Telegram-чат марафона. Решение данных задач мы рассмотрим с вами во время следующего прямого эфира. Удачи в выполнении задания!

Полезные ссылки
Статья с VC.RU
Youtube Visiology
Подробное описание из справки

